Minimizing Application Area: A Practical Way to Reduce Software Supply-Chain Risk
From the 2018 AUR compromise to Log4Shell, every dependency expands your trust surface well beyond the code itself. Here's how I think about shrinking it.
Minimizing Application Area: A Practical Way to Reduce Software Supply-Chain Risk
The First Time I Paid Attention
I was not looking for it. I came across it the way most people come across security incidents, reading through community forums and following a thread that kept getting more interesting.
It was 2018. Someone had adopted an orphaned package in the Arch User Repository. The package was acroread, a community-maintained build recipe for Adobe Acrobat Reader on Linux. Nothing from Adobe's official infrastructure. Just a package that existed in AUR because someone had been maintaining it, and then stopped.
The person who took it over had other plans.
They modified the PKGBUILD, the script that tells the AUR tooling how to fetch, build, and install software. Instead of just pulling and installing Acrobat Reader, it now fetched remote code from an external source and ran it on the user's machine during installation. That part was deliberate. What happened next was not.
The attacker was sloppy. The payload crashed. It generated enormous, obvious system logs. And it dropped a file in the user's home directory called compromised.txt. Not subtle. The community picked up on it quickly, the package was flagged, and the incident was contained fairly quickly.
It never affected me directly. The executable never ran on my machine. But I kept turning it over in my head for a while after.
What stuck was not the technical detail of the exploit. It was the shape of the thing. Someone had installed a package they probably assumed was safe because it had been around for years, because it had a community, because it solved a real need. They had no idea the person maintaining it had changed. They had no idea the build script had been quietly modified. They ran the install because that is what you do.
The community caught this one because the attacker was careless. A quieter payload, no compromised.txt sitting in your home folder, logs that looked unremarkable, and this incident ends differently. A lot more quietly.
That is what it made concrete for me. A package is not just code. It is a maintainer, a build script, an install path, and a trust decision. One you may not have consciously made at the moment it mattered.
I did not change how I worked overnight. But I started paying more attention. And a few years later, I had a reason to pay a lot more attention.
The Log4j Moment
Log4j in late 2021 was a completely different kind of incident. Nobody hijacked a maintainer account. Nobody snuck a malicious script into a build recipe. It was a critical remote code execution vulnerability in a widely used Java logging library. The kind of thing that sends security teams into weekend firefighting mode.
What made it personal for me was not the severity of the vulnerability. It was that I had no idea we were using it.
At the time, most of my software was MATLAB and Python. There was one Java component in the mix, a bridge that connected the two environments. It was small but important. I had written some of it, relied on a few libraries for the rest, and mostly stopped thinking about it once it worked.
When Log4j broke, I went looking. I dug into the dependency tree of that bridge, tracing what it pulled in. Turns out the bridge used a WebSocket library. That WebSocket library pulled in something else. And that something else depended on a version of Log4j with the vulnerability. None of those dependencies were things I had installed with any intention. They were just there, quietly, doing their job.
The fix was not complicated once I found it. I upgraded the WebSocket library to a version that pulled in the patched Log4j release. Done.
But the realization took longer to sit with.
I had not installed Log4j. I had not thought about Log4j. I could not have told you Log4j was in my system if you had asked me the day before the vulnerability dropped. And yet my application depended on it. My application's security depended on it being patched.
The AUR incident had been about trust and maintainers. Log4j was about visibility. Two different problems, but the same underlying gap: I was responsible for more than I had consciously accounted for.
Modern applications are assembled, not just written. They depend on packages you chose, packages those packages chose, build tools, runtime environments, and an entire ecosystem of code you may have never read and possibly could not name. The gap between "what I wrote" and "what my application depends on" is where supply-chain risk lives.
This is what I mean when I talk about application area. Not just the files you authored. Not just the top-level packages in your requirements file. Everything the system depends on to build, run, and stay secure. And connected to that is something I started calling the trust surface: the maintainers, registries, release pipelines, install scripts, update streams, and runtime behaviors the system has to trust in order to function.
A dependency is not just code. It is a new trust boundary.
Every package you add brings with it people you may not know, pipelines you do not control, and future updates that will flow into your system, often without you reviewing them. Most of the time that is fine. But fine by habit is not the same as fine by design.
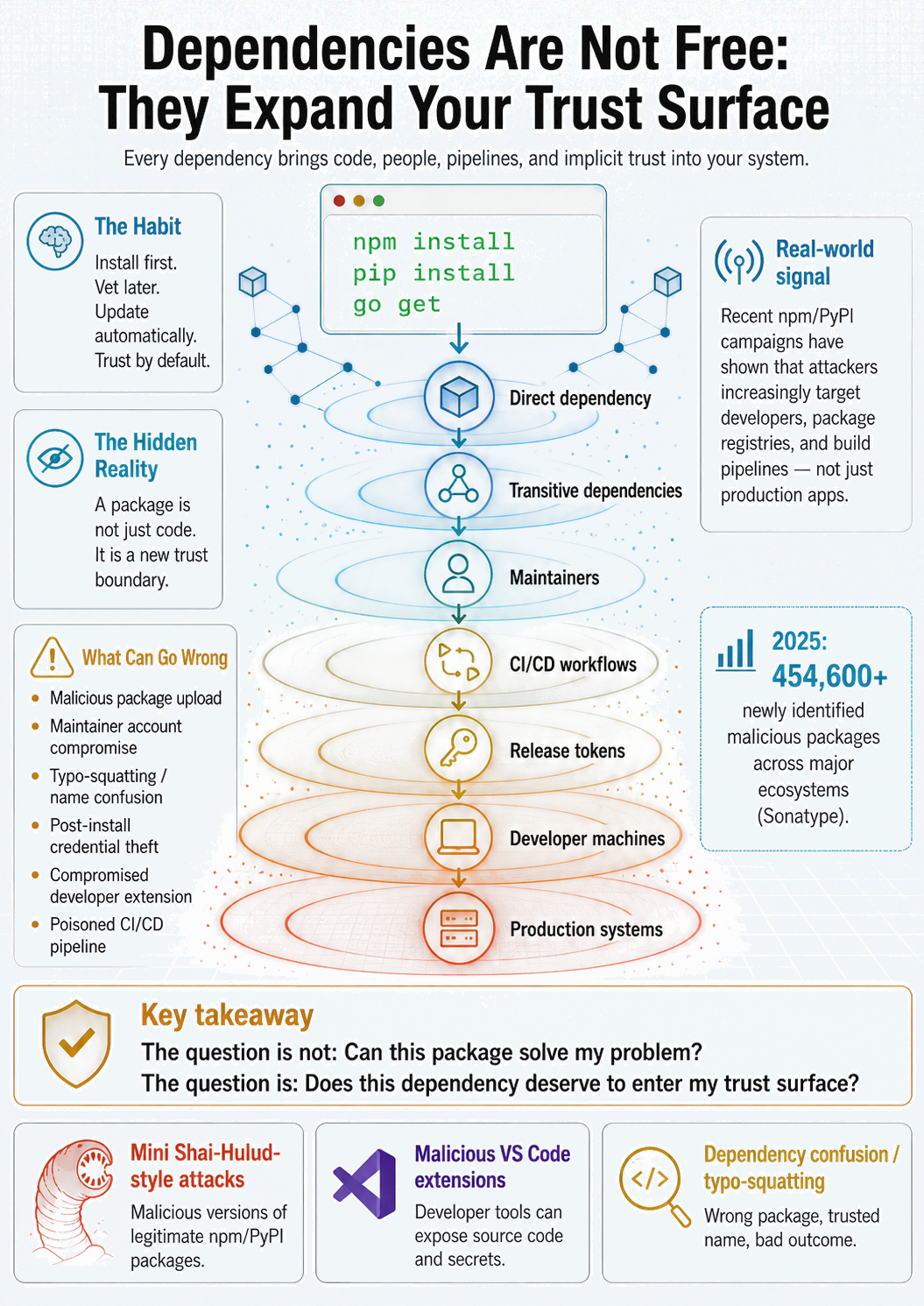
What the Attack Surface Actually Looks Like
Most people, when they think about supply-chain risk, think about production runtime dependencies. The packages in your requirements.txt or package.json. The libraries your application loads when it starts up. That is the obvious part.
It is also only part of the picture.
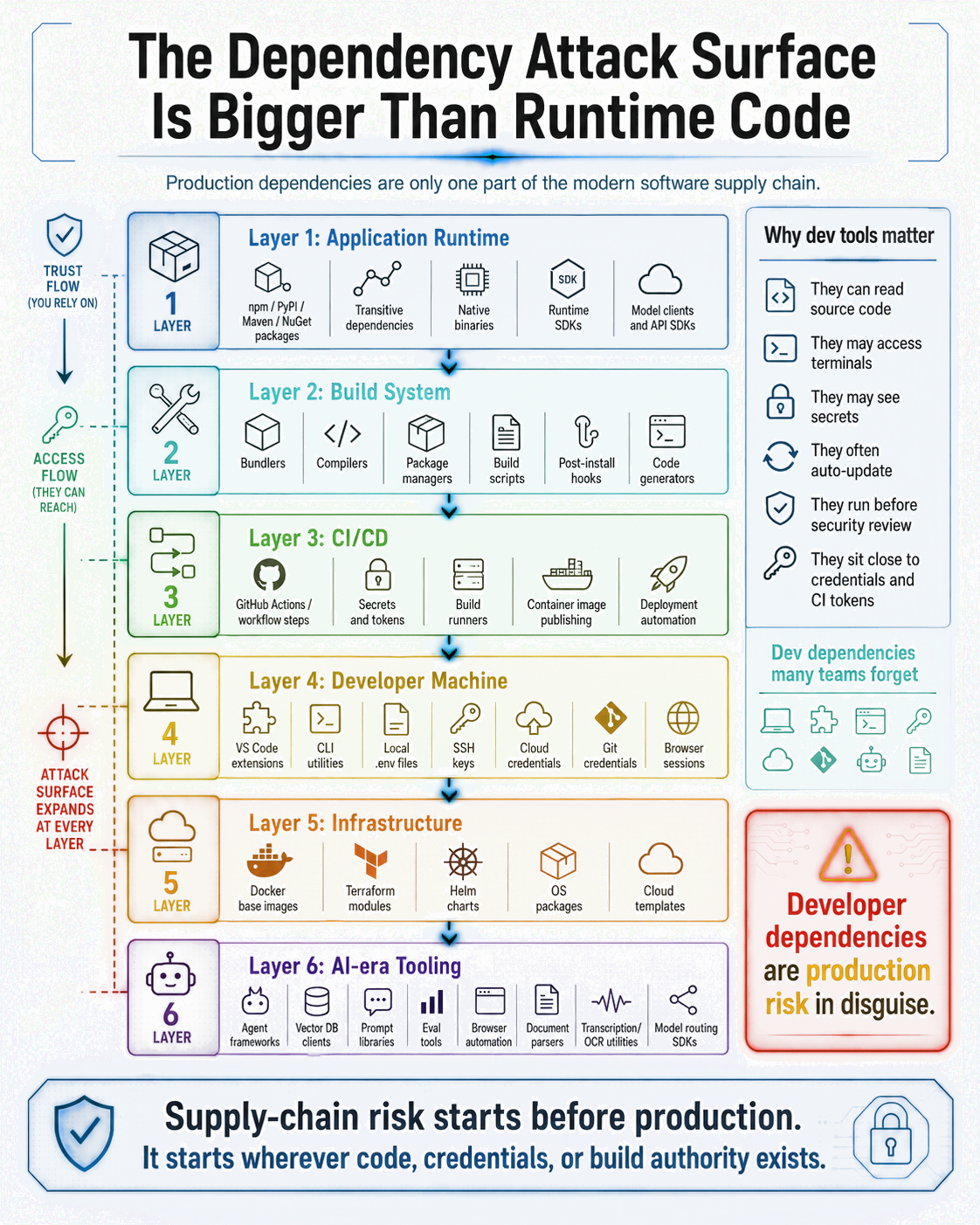
Think about everything that has to work correctly, and has to be trustworthy, for a piece of software to exist and run securely. Start with the runtime dependencies, yes. But then keep going.
There are the build tools: the compiler, the bundler, the package manager itself. There are the pre-install and post-install hooks that run during package installation, often with no output and no review. There are the CI/CD pipelines, the GitHub Actions, the deployment scripts, and the container registries that your application flows through on its way from code to production. There are Docker base images, often pulled from public registries with a one-line reference, and whatever is baked into them.
Then there is the developer machine. The IDE and its extensions. The CLI tools installed globally. The local build environment. The .env files sitting on disk. The SSH keys. The cloud credentials cached in config files or environment variables. A developer's machine is not a sandboxed environment. It is a hub: it touches source code, it has commit access, it holds secrets, it runs code. It is part of the attack surface whether or not it appears on any architecture diagram.
Infrastructure adds another layer. Cloud provider SDKs, Terraform modules pulled from public registries, Kubernetes configurations, database clients. Each of those has maintainers and update cadences and trust requirements of their own.
And then there is everything that has become normal in AI application development: LLM SDKs, agent orchestration frameworks, vector database clients, embedding libraries, document parsers, evaluation tools, tracing and observability exporters, browser automation packages. The AI tooling ecosystem is genuinely useful and genuinely fast-moving, which is exactly the combination that tends to produce casual dependency decisions.
A team building an AI application in 2024 might add six or seven meaningful new packages in a single sprint, each with its own dependency tree, its own release cadence, and its own exposure to the problems described above. Nobody is doing that carelessly. But speed creates assumptions, and assumptions create blind spots.
The point is not that any of these layers are inherently dangerous. Most of the time, most of them are fine. The point is that when you think about what your application depends on, the honest answer includes all of this. Not just the runtime. The build. The CI. The developer environment. The tools your team uses every day.
Supply-chain risk does not start when code reaches production. It starts wherever code, credentials, or build authority exists.
Reducing Risk, Part 1: Choose Less and Choose Better
I am not against dependencies. I am against casual dependencies.
There is a version of this conversation that turns into "just build everything yourself," which is not what I am saying. Open-source packages exist because hard problems have been solved well by people who thought carefully about them, and using that work is not a weakness. The question is whether you are reaching for a package because it genuinely belongs in your system, or because it was the fastest path to closing a ticket.
My personal rule is straightforward. If I can implement the same thing safely, clearly, and maintainably in a couple of hours, I usually write it myself. Not out of principle. Not because I distrust the package. Because the overhead of adding a dependency, including the ongoing obligation to track it, update it, and audit it, often outweighs the time saved when the problem is small.
This rule has hard limits, and I take them seriously. I do not write my own cryptographic primitives. I do not build my own authentication flows or session management. I do not roll my own database drivers, payment processing, or ML runtimes. Those domains are genuinely hard, security-sensitive, and well-served by mature packages that have earned real trust over years of production use. Using them is the correct call, not a shortcut.
But a lot of software problems are not in those domains. Simple glue logic between two systems. A thin wrapper around an HTTP client. A small retry mechanism with backoff. A config file parser for a format you control. A prompt construction helper. A narrow adapter around an already-approved SDK. These are the cases where I have started asking whether I actually need a package, or whether four functions in a file would do the same job with less exposure.
If the code is small, boring, testable, and domain-simple, owning it may be safer than importing it.
The other side of choosing less is choosing better when you do add something. Not all packages carry the same risk. A library with ten years of production use, thousands of dependents, an active maintainer team, a clear release history, and a track record of patching vulnerabilities quickly is a different proposition from a package that was published two months ago, has one maintainer, and forty GitHub stars. That does not mean new packages are automatically suspect. It means the evaluation should be proportional to what you are asking the package to do and how close it sits to anything sensitive.
Dependency minimalism is not anti-package. It is pro-judgment. It is the habit of asking, before you install, whether this thing has actually earned a place in your application.

Reducing Risk, Part 2: Control, Verify, and Contain
Once you have decided a dependency belongs in your system, the work is not done. You have made a trust decision, but trust decisions need ongoing maintenance.
Start with version pinning. Pin the exact version, not a range. A floating specifier like ^2.x or >=1.4 is a standing instruction to accept whatever comes next, including any future release that changes behavior or, in a worst case, carries a compromise. Version pinning does not make dependencies safe. It makes them repeatable. That is not a small thing. Repeatability is what lets you reason about what is actually running in your system, reproduce builds reliably, and notice when something changes.
Commit your lockfiles. This is still surprisingly controversial on some teams. A lockfile records exactly what was installed, not just what was requested. Without it, two developers running a fresh install on the same codebase might get different versions of transitive dependencies depending on when they run it. The lockfile removes that ambiguity. It belongs in version control.
Use hashes when the risk context warrants it. Hashes increase confidence in delivery integrity. They do not prove author intent. If a registry is compromised and the malicious artifact is hashed and served in place of the legitimate one, a hash check confirms the artifact matches what was recorded, not that it is safe. Hashes are one layer of a defense-in-depth approach, not a solution on their own.
Be deliberate about updates. This is the one that creates the most friction in practice, because automatic updates feel like they remove maintenance burden. Automatic updates are convenient, but controlled updates are more auditable. For most production dependencies, you want to update intentionally: review the changelog, understand what changed, run it through your test pipeline, and deploy it in a window you control. Not because updates are dangerous, but because you want to understand what changed and when.
For developer tools specifically, treat updates with more care than you might expect. IDE extensions, build tooling, browser automation packages, and CLI utilities that sit on developer machines often have access to source code, environment variables, SSH keys, and cloud credentials. They auto-update by default in most cases. It is worth reviewing which tools have that behavior and deciding whether you are comfortable with it.
The last piece is containment. When you need to evaluate a new package, or run a build involving tooling you do not fully trust yet, use an isolated environment. A dev container, a virtual machine, an ephemeral cloud environment with no access to production credentials. The goal is to limit the blast radius of a problem you have not discovered yet. One compromised sandbox should not become one compromised laptop, one compromised cloud account, and five compromised client projects.
None of this is expensive once it is habitual. The cost of doing it is low. The cost of not doing it shows up at the worst possible time.

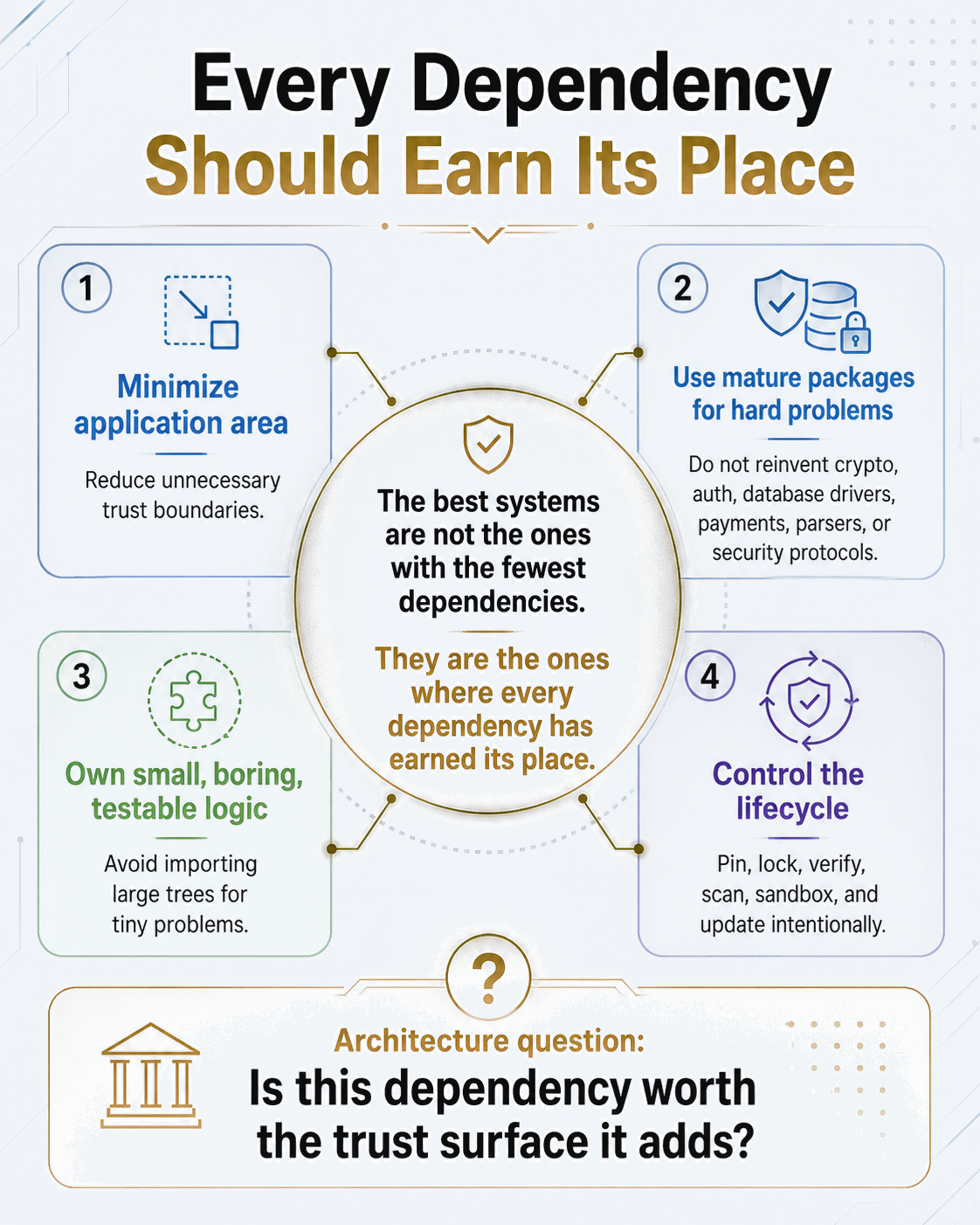
Every Dependency Should Earn Its Place
I want to be clear about what this is not.
This is not an argument for building everything from scratch. It is not a warning that open-source is dangerous or that community-maintained packages are inherently risky. The reason small engineering teams can build production-grade systems at all is largely because of decades of shared work, well-maintained libraries, and ecosystems that make hard problems approachable. That is genuinely valuable and worth protecting.
What I am arguing for is a change in how we think about the moment we add something.
There is a habit that forms quickly in software development, especially on fast-moving teams: the reflex to install first and think later. A package exists, it solves the immediate problem, the README looks fine, so it goes in. That works most of the time. Software ships, systems run, nothing bad happens. The problem is that it trains us to treat dependency decisions as developer convenience decisions, when they are actually architecture decisions.
Every package you add expands your application area. It increases your trust surface. It brings in people and pipelines and update cadences you are now implicitly relying on. It creates a maintenance obligation that will outlast the sprint it was added in. Most of the time the tradeoff is worth it. But it should be a conscious tradeoff, not a default.
The incidents I described at the beginning of this article, the AUR package in 2018 and the Log4j chain in 2021, were very different in their mechanisms. One was active and malicious. The other was a vulnerability that had been sitting in plain sight. But both arrived through the same gap: a dependency that nobody had fully accounted for. The exposure was already there before anyone knew to look for it.
That is the gap worth closing. Not through fear, not through rejection of external code, but through the habit of asking one more question before you commit to a new dependency.
The best systems are not the ones with the fewest dependencies. They are the ones where every dependency has earned its place.
The real question is not "Can I install this package?"
The real question is: "Does this dependency deserve to become part of my application's trust surface?"
Notes
The AUR example refers to the 2018 compromise of the acroread package in the Arch User Repository, not Adobe's official infrastructure. The Log4j example refers to CVE-2021-44228 / Log4Shell, a critical remote-code-execution vulnerability disclosed in December 2021.