The Hardest Part of Legal RAG Was Teaching It Not to Answer
Lessons from building LexAI, a legal RAG experiment around India's transition from IPC, CrPC, and IEA to BNS, BNSS, and BSA.
The Hardest Part of Legal RAG Was Teaching It Not to Answer
What I learned building LexAI, a verification-first RAG experiment for India's criminal law transition from IPC, CrPC, and IEA to BNS, BNSS, and BSA.
The interesting part of a legal RAG system is not whether it can produce a fluent paragraph. Any capable model can do that. The harder question is whether the system can constrain the model before generation, verify it after generation, and make uncertainty visible when the answer has not been earned.
That was the real experiment behind LexAI: not a chatbot with legal PDFs attached, but a controlled pipeline for routing, retrieval, citation discipline, and failure handling.
TL;DR: LexAI was not an attempt to replace lawyers or claim "zero hallucination." It was an engineering experiment in making legal RAG less eager, more traceable, and more honest about uncertainty. The biggest lesson was simple: the model can write the answer, but the surrounding system has to earn the right to show it.
This write-up is about system architecture, not legal advice.
Key Takeaways
| Takeaway | Why it matters |
|---|---|
| Ambiguity should stop the pipeline | A bare "Section 302" can refer to different legal eras. Guessing is not helpful; it is risky. |
| Deterministic facts need deterministic paths | Exact section lookup and old-to-new mappings should not depend on model memory. |
| Retrieval quality is necessary but not sufficient | Good context reduces risk, but generated citations and claims still need verification. |
| Citations must be checked against retrieved sources | A polished answer with an unsupported citation is still a bad answer. |
| Traceability is part of the product | In high-stakes AI, confidence is not enough. Users and builders need to inspect how an answer was produced. |
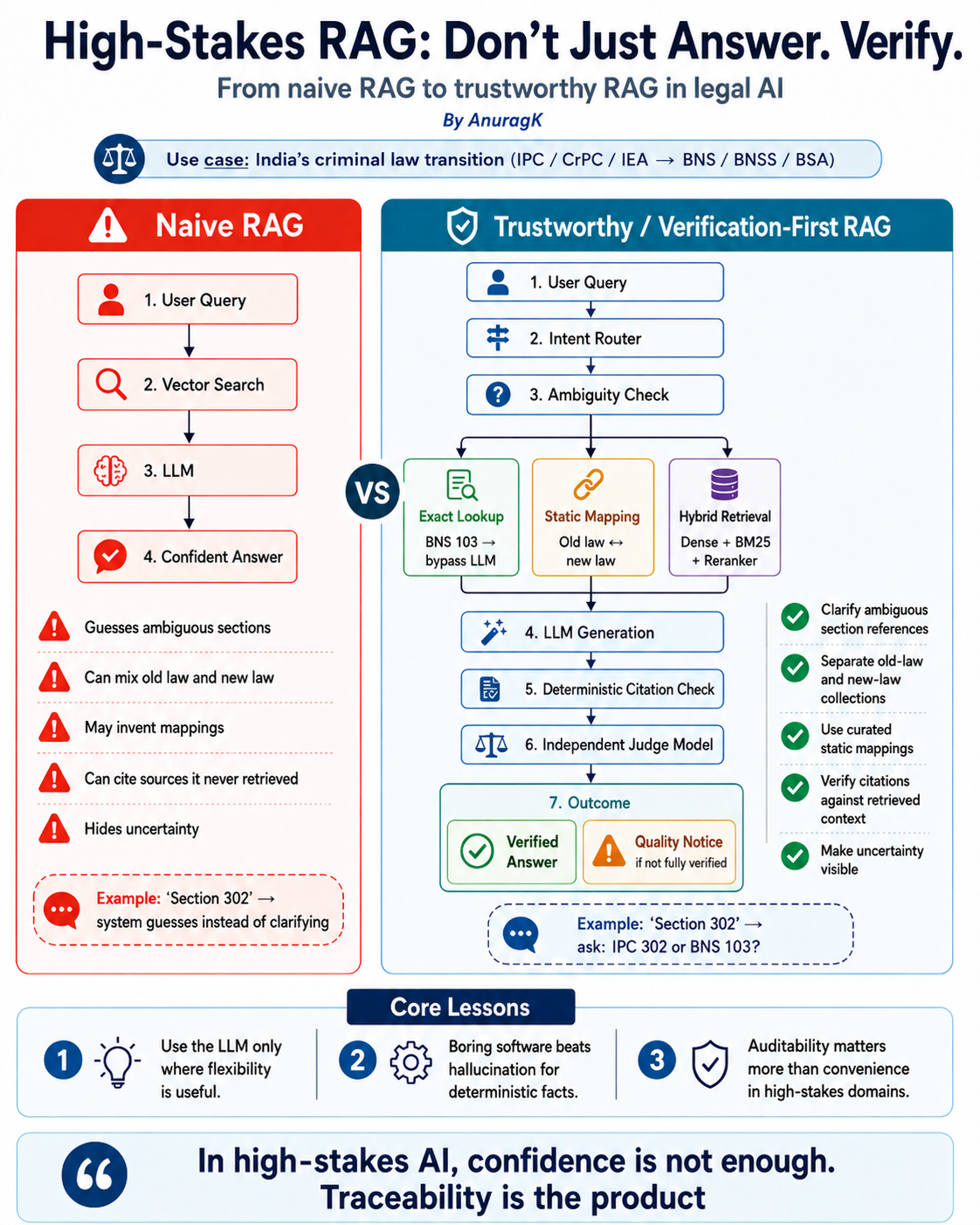
Naive RAG optimizes for producing an answer. Verification-first RAG adds routing, deterministic controls, citation checks, judge review, and visible uncertainty.
The Conversation That Started It
LexAI started from a casual family discussion, not from a product roadmap. My father is a lawyer. My brother is studying law. One day we were discussing the section for cheating under India's new criminal laws. My instinctive reference was the one almost everyone knows: IPC 420. But under the new Bharatiya Nyaya Sanhita, the corresponding reference is BNS 318.
That small moment stayed with me.
The transition from IPC, CrPC, and the Indian Evidence Act to BNS, BNSS, and BSA is not only a change in law names. It changes section numbers practitioners, students, clerks, police officers, journalists, and citizens have used for decades. When that mental map shifts, legal research becomes both a knowledge problem and a migration problem.
So I did the obvious modern thing: I asked ChatGPT. The answer looked polished. That was not the scary part. The scary part was that nothing forced the model to distinguish old law from new law, prove citations, admit ambiguity, or show its route.
It could be right. It could also be polished, plausible, and unsupported.
That became the engineering question behind LexAI: could I build a legal RAG system that I would trust more than a normal chatbot answer, not because the model was magical, but because the architecture constrained it?
WARNING: A wrong citation in legal AI is not a typo. It can point someone toward the wrong law, the wrong punishment, or the wrong procedural path.
The Design Principle
LexAI is best understood as a controlled pipeline, not as a chatbot with legal documents attached.
That distinction matters. A chatbot-centered architecture usually treats retrieval as extra context for the model. LexAI treats the model as one stage inside a larger system. Before generation, the query is routed, legal entities are extracted deterministically, ambiguous references are stopped, exact lookups bypass the LLM, and old-to-new mappings come from static data. After generation, citations are checked against retrieved sources, an independent judge reviews grounding, failed answers can be rewritten using the same context, and unresolved uncertainty is exposed through a quality notice.
The design principle is simple: use software controls wherever the task is deterministic, and use the LLM only where language flexibility is actually useful.
Why Naive RAG Is Dangerous in Legal Domains
A basic RAG system sounds reasonable on paper: embed the user's question, search a vector database, send retrieved chunks to an LLM, and ask the LLM to answer with citations. That pattern works for many knowledge-base and documentation use cases. It is also dangerously incomplete for legal research.
The problem is not only hallucination in the loose sense of "the model made something up." In legal RAG, the failure modes are more specific: ambiguous references can be silently resolved, old and new law can be mixed, mappings can be inferred instead of looked up, generated citations can point to sources never retrieved, and confident formatting can hide uncertainty.
Here is the naive flow:
Alt text suggestion: Naive RAG flow showing a user query moving through vector search and an LLM into a confident answer, with risk annotations for ambiguity, old/new law mixing, invented mappings, unretrieved citations, and hidden uncertainty.
The core issue is eagerness. Naive RAG tries very hard to answer. Legal RAG needs to try very hard to be allowed to answer.
LexAI as a Verification-First RAG Architecture
LexAI was built around a different posture: retrieve, generate, verify, and expose uncertainty when verification fails. The system focuses on India's criminal law transition from IPC, CrPC, and IEA to BNS, BNSS, and BSA. The purpose is not to provide legal advice. It is to explore how a legal research assistant could help users navigate changed references while reducing wrong-citation and old/new-law confusion.
At a high level, the architecture has these components:
| Component | Role in the system |
|---|---|
| Query router | Classifies user intent before retrieval begins. |
| Law parser | Extracts act and section references deterministically using regex. |
| Ambiguity detection | Stops vague section-only queries and asks for clarification. |
| Exact lookup path | Returns direct section text without involving the answer LLM. |
| Static mapping path | Uses audited old-to-new mappings instead of model memory. |
| Hybrid retrieval path | Combines dense search, BM25, and reranking for conceptual queries. |
| Old/new collection separation | Keeps legacy and new-law text in separate retrieval namespaces. |
| LLM generation | Produces structured, source-grounded answers from supplied context. |
| Deterministic citation verification | Checks generated citations against retrieved references. |
| Independent judge model | Reviews whether the answer is grounded in the retrieved context. |
| Rewrite loop | Attempts to repair unsupported or badly cited answers using the same context. |
| Quality notice | Makes verification failure visible to the user. |
| Trace logging | Records intent, retrieved refs, generated answer, and verification metadata. |
The architecture:
Alt text suggestion: LexAI verification-first RAG architecture showing routing, ambiguity handling, exact lookup, static mapping, hybrid retrieval, context building, generation, citation checking, judge verification, rewrite loop, verified answer, and quality notice.
The key design decision is that the LLM is one component inside a larger control system.
KEY IDEA: The model can write the answer. The system has to prove it.
Failure-Mode-Driven Architecture
I find it more useful to describe this kind of system by failure mode than by feature list. "We use a vector DB and a reranker" is less interesting than "we are trying to prevent dense retrieval from missing exact statutory language."
| Failure mode | Naive RAG behavior | LexAI design choice | Why it matters |
|---|---|---|---|
| "Section 302" is ambiguous | Guess and answer | Ask clarification | Prevents silent wrong-era resolution |
| Exact section lookup | Use LLM anyway | Bypass LLM | Deterministic facts should use deterministic paths |
| Old/new law contamination | Rely on metadata filters | Separate collections | Removes an entire class of retrieval bugs |
| Legal mappings | Model guesses | Static JSON mappings | Auditable and correctable |
| Fabricated citations | Trust generated text | Citation verifier | Blocks unsupported citations |
| Unsupported reasoning | Looks plausible | Judge model | Checks grounding beyond citation identity |
| Verification failure | Hide uncertainty | Quality notice | Makes uncertainty visible |
This is the architectural pattern I kept returning to: remove the LLM from places where flexibility is not valuable. Regex is boring. Static lookup is boring. Separate collections are boring. But in legal retrieval, boring software is often exactly what you want.
NOTE: Boring software is underrated when the cost of being interesting is hallucination.
Naive RAG vs Verification-First RAG
| Dimension | Naive RAG | Verification-First RAG |
|---|---|---|
| Default posture | Answer the query | Earn the answer |
| Ambiguous references | Resolve silently | Ask for clarification |
| Exact legal sections | Retrieve and generate | Direct deterministic lookup |
| Old/new legal transition | Let retrieval/model infer | Use static audited mappings |
| Corpus boundaries | Metadata filters | Separate old/new collections |
| Retrieval strategy | Often vector-only | Dense + BM25 + reranker |
| Citation handling | Generated by model | Checked against retrieved refs |
| Grounding check | Trust prompt compliance | Deterministic check plus judge |
| Failure handling | Return polished answer | Rewrite or attach quality notice |
| Auditability | Hard to reconstruct | Trace intent, sources, verification |
Verification-first RAG is not perfect. The difference is that failure becomes observable. Once failure is observable, it can be reviewed, measured, and fixed.
Retrieval Design: Where the LLM Should Step Back
Retrieval is often discussed as one step. In practice, LexAI uses different paths for different query types.
Exact Lookups Should Bypass the LLM
If the user asks for BNS 103, the system does not need a creative answer. It needs the section text. In LexAI, an exact lookup with one result bypasses the answer LLM. This removes unnecessary generation risk and also improves latency: in the 20-case evaluation, exact lookup and ambiguity paths completed in about 0.17 seconds.
Ambiguous Queries Should Not Be Answered
Bare section references are common in legal conversation, and dangerous during a legal transition. Section 420 is not enough information. LexAI routes these cases to an ambiguous intent and returns clarification candidates instead of generating an answer.
Static Mappings Beat Model Memory
The old-to-new legal transition is a mapping problem. IPC 420 maps to BNS 318 in the cheating context. LexAI uses a static mapping file with more than 2,000 IPC, CrPC, and IEA to BNS, BNSS, and BSA correspondences. An LLM's parametric memory is not an auditable source of truth.
Separate Collections Beat Only Metadata Filters
LexAI keeps new-era law and old-era law in separate vector collections:
legal_docs_normalizedfor new-era lawold_legal_docs_normalizedfor old-era law
This is stricter than putting everything in one collection and relying only on an era metadata filter. Separate collections make old/new contamination structurally harder because the wrong-era text is not in the namespace.
Hybrid Retrieval Beats Vector-Only Search
Legal text has two personalities. It is semantic, but it is also exact. Dense retrieval is good at meaning. BM25 is good at exact words and statutory phrasing. A reranker can then re-score the merged candidate set with a stronger relevance signal.
LexAI's semantic path uses:
| Retrieval layer | Purpose |
|---|---|
| Dense embeddings | Capture semantic similarity between user language and legal text. |
| BM25 sparse retrieval | Preserve exact statutory terms and section phrasing. |
| Deduplication and merge | Combine evidence from dense and sparse hits. |
| Reranker | Re-score candidates before final context construction. |
Vendor choices are less important than the principle. LexAI used Zilliz, dense embeddings, BM25, and a reranker in the stack. The architectural lesson is that legal retrieval should not depend on vector similarity alone.
Output Verification Design
Retrieval reduces the chance of hallucination. It does not eliminate it. Even with strong context, the model can still cite a section that was not retrieved, forget citations entirely, cite using a format the system cannot verify, or make a claim that is not supported by the source it cites.
LexAI handles this with a two-phase verification flow.
Alt text suggestion: Verification loop showing generated answer, citation extraction, citation comparison against retrieved context, judge model, verified answer, rewrite using the same context, and quality notice after failed attempts.
Structured Output
The answer model returns structured JSON rather than free-form prose. The important fields include the answer markdown, relevant sections, and legacy change summary. This forces the model to commit to what it cited and gives the verifier something concrete to inspect.
Citation Extraction and Allowed References
The deterministic verifier extracts bracketed citations from the answer and compares them with the ref_display values in the retrieved context. If the context contains BNS 103, the answer is allowed to cite BNS 103. Subsection matching is also handled, so BNS 103(1) can be accepted when the base section BNS 103 was retrieved.
Hard failures include:
- empty answer
- retrieved context exists but the answer has no citations
- any citation does not match the retrieved source set
This check has no LLM cost. It is a deterministic gate that should run every time.
Independent Judge Model
Citation identity is not enough. A model can cite a real retrieved section and still make an unsupported claim about it. That is why LexAI also uses an independent judge model. The judge receives the user query, retrieved context, and generated answer. Its job is not to answer the legal question; its job is to decide whether the answer is grounded in the supplied context. This is a risk control, not a guarantee.
Rewrite Loop and Quality Notice
If verification fails, LexAI attempts a rewrite using the same retrieved context. The rewrite step is not allowed to fetch new sources or invent new ones. If verification still fails after the configured attempts, the answer can be returned with a quality notice rather than being presented as fully verified.
Example verification metadata:
{
"verification": {
"passed": false,
"score": 0.61,
"method": "hybrid",
"rewrite_attempts": 2,
"notice_attached": true
}
}
This metadata is not just for logging. It can power UI trust indicators, reviewer queues, eval dashboards, and failure analysis.
KEY IDEA: In high-stakes AI, confidence is not enough. Traceability is the product.
Framework Decision: Auditability Over Convenience
I avoided heavy RAG or agentic frameworks for this experiment. That is not an anti-framework position. Frameworks are useful, especially for prototyping.
For this experiment, auditability mattered more than convenience. I wanted every prompt, route, verification gate, and execution branch to be readable and traceable. If the system asked for clarification, used static mapping, or failed verification, I wanted the path to be obvious.
That is why LexAI is closer to an explicit application pipeline than an autonomous agent. There is a router, a parser, retrieval paths, a context builder, a generator, verifiers, a rewrite loop, and trace capture. Each piece has a job.
This makes the system less magical. That is the point.
Evaluation Results
In my first 20-case evaluation, 17 passed, 2 needed human review, and 1 failed expected-source validation.
This was not a formal benchmark. It was a small architecture validation run across exact lookup, cross-walk, ambiguity handling, semantic search, decomposed search, comparison, and follow-up queries. Here, "passed" means I reviewed the result against the expected source behavior for that query type. The purpose was to inspect behavior, not to claim broad legal accuracy.
| Category | Result |
|---|---|
| Total cases | 20 |
| Passed | 17 |
| Needed human review | 2 |
| Failed expected-source validation | 1 |
| Key lesson | Failure was traceable and fixable |
The failed case mattered. IPC 304A returned the wrong expected source pair: IPC 304 and BNS 105 instead of the expected IPC 304A and BNS 106. That is exactly the kind of failure this architecture should make visible. It pointed toward parser and mapping behavior around alphanumeric sections, giving an engineer something concrete to investigate.
There were also latency lessons. Exact lookup and ambiguity handling were fast. The slowest paths were answer generation, judge calls, and rewrite cascades. Verification improves trust posture, but it has a cost.
Lessons Learned
| Lesson | What changed in the architecture |
|---|---|
| Use LLMs only where flexibility is useful | Exact section parsing, exact lookup, and legal mappings use deterministic paths. |
| Boring software beats hallucination for deterministic facts | Regex, static JSON, separate collections, and citation matching carry much of the trust burden. |
| Ambiguity should trigger clarification, not generation | Bare section references stop the pipeline and return clarification candidates. |
| Retrieval quality is necessary but not sufficient | Good context still needs post-generation verification. |
| Citations must be verified against retrieved context | The system builds an allowed reference set and checks generated citations against it. |
| Uncertainty should be visible | Failed verification leads to rewrite attempts or a quality notice. |
| Auditability is an architectural requirement | Traces capture query intent, retrieved refs, answer metadata, verification status, and rewrite attempts. |
The common thread: in serious domains, do not ask the model to carry responsibilities normal software can handle more reliably.
What I Would Improve Next
The first version of LexAI answered the architectural question I cared about: can the system make legal RAG less eager and more verifiable? There is still plenty to improve.
| Improvement | Why it matters |
|---|---|
| Curated eval suite | Raw traces should become reviewed eval cases with expected sources and accepted answer patterns. |
| Retrieval recall by intent | Exact lookup, cross-walk, vector search, and decomposed queries need separate quality measurements. |
| Alphanumeric section handling | The IPC 304A failure suggests parser and mapping behavior needs targeted review. |
| Latency budgets | Judge and rewrite loops should be measured and controlled. |
| Citation repair pass | Some failures may be fixed more cheaply before invoking a full rewrite. |
| Verification dashboard | Pass rates, quality notices, judge failures, and retrieval misses should be visible over time. |
| Human review workflow | High-stakes outputs need a path for expert review, not only automated checks. |
The next maturity step is not a bigger model. It is a better eval discipline.
Closing
LexAI changed how I think about RAG. The hard part was not connecting a vector database to an LLM. The hard part was deciding where the system should refuse to improvise: exact sections should be looked up, legal mappings should be read from an auditable table, ambiguous references should trigger clarification, generated citations should be checked, and unsupported answers should carry visible uncertainty.
The future of serious RAG is not just systems that answer faster. It is systems that know when the answer has not been earned yet.